本文主要解决的是SLU(Spoken Language Understanding)的跨语言迁移,即针对于同一领域从高资源语言SLU迁移到低资源语言SLU,同时构建了一个英语、西班牙语、泰语的平行语料。NAACL2019
Introduction
本文建立了一个跨语言的SLU数据集:

数据集的收集过程为:首先让英语母语者为三个领域内的每一个intent生产句子(比如:会怎么样询问天气),这样收集了43000条英语句子;随后让两个标注者基于此标注intent和slots,如果两者有分歧,则请求第三个标注着来做最终裁定;对于西班牙语和泰语的样本,则是让一小部分母语者将英语的一部分样本(随机采样)翻译成对应的语言;对于西班牙语的标注同上,出现分歧时就让第三个同时精通于英语和西班牙语的标注着进行裁定;而对于泰语,由于找不到同时精通于英语和泰语的标注者,所以处理方式就是直接丢弃掉出现标注分歧的样本。
NLU models
作者主要比较了以下几类跨语言迁移的方法:
- 将高资源的语言训练数据翻译为低资源语言训练数据,类似于数据增强
- 使用跨语言的预训练词向量
- 使用跨语言的机器翻译编码器作为上下文表征
实验发现:给定少量的目标语言训练样本,后两种方法优于直接数据增强;并且第三种方法优于静态词向量模型;但是在给定少量目标语言的前提下,这些跨语言模型不如仅单语言ELMo方法,这说明现有的跨语言模型还不能有效的提取语言特征。
Basic architecture:

- 首先会让给定句子通过一个句子分类器,去识别该句子属于哪个领域(Alarm、Reminder、Weather之一)
- 之后使用特定领域的模型去联合预测intent和slots
而不同方法主要对照的点在于词向量编码层,可选方案如下:
- Zero embeddings: 使用一个词向量矩阵随任务进行训练,这个矩阵将会在一开始被初始化为零。
- XLU embeddings: 使用预训练好的跨语言的词向量矩阵(称为XLU embeddings,见引文:Ruder et al., 2017, A survey of cross-lingual word embedding models)编码一个词,并与上述随任务训练的zero embeddings进行拼接,这里的跨语言词向量矩阵是fixed的。
- Encoder embeddings: 使用一个通过某种方法(后文会介绍)预训练的双向LSTM句子编码器,提取其最上层的隐层向量作为该句子中每个词语的表示,并且将这些向量与随任务联合训练的zero embeddings拼接,作为这个词最后的表示。
Encoder models
采用了两层的双向LSTM编码器。实验比较了以下三种具体的策略(模型结构和预训练目标):
- CoVe: 按照McCann et al, 2017, Learned in translation: Contextualized word vectors,训练一个机器翻译模型,将低资源的语言(西班牙语或泰语)翻译成英语,然后将机器翻译模型中的编码器作为句子编码器。
- Multilingual CoVe: 训练一个机器翻译模型,能够同时将低资源的语言翻译成英语和把英语翻译成低资源语言,模型的翻译方向取决于解码器的第一个和目标语言相关的输入token(即在双语翻译的时候,decoder端的target language会增加一个语言标识符)(详细见Yu et al., 2018a, Multilingual seq2seq training with similarity loss for cross-lingual document classification)。在预训练这一模型的过程中,编码器是语言不可知的(即编码器无法获知所翻译的句子具体属于何种语言),因此可以期望模型学到跨语言的语义特征。
- Multilingual CoVe w/ autoencoder: 作者使用的是一个双向的机器翻译模型,同时联合了自编解码器的训练目标。比如对西班牙语-英语的句子对而言:给定西班牙语的输入句子,模型会根据解码器输入的第一个token,要么生成对应的英语翻译,要么生成这个句子本身。给定英语输入句子也同样,解码器应该根据第一个token,要么输出其对应的西班牙语翻译,要么重现这个句子本身。这样设计训练目标的动机是:让编码器学习到泛化能力更强的跨语言的语义表示,因为这里和上一种训练方式不同,输入句子的语言并不决定输出句子的语言。
此外,对于西班牙语,作者还使用了预训练的ELMo编码作为对照,但西班牙语的ELMo编码相当于仅仅是在西班牙语的语料上进行预训练的,所以它并不是跨语言的编码。
Experiemnts
Cross-lingual learning
作者首先在以下设定下使用基础模型进行了实验:
- Target only: 只使用低资源的目标语言作为训练样本
- Target only with encoder embeddings: 只使用低资源的目标语言作为训练样本,但是其编码层采用预训练的encoder embeddings
- Translate train: 将英语的训练样本翻译到目标语言,并与目标语言的训练样本融合,其中机器翻译采用的是Facebook的机器翻译系统,标注的slot信息通过attention权重(引文:Yarowsky et al., 2001, Inducing multilingual text analysis tools via robust projection across aligned corpora)映射到翻译后的句子
- Cross-lingual with XLU embeddings: 将英语和目标语言的训练样本混合后进行训练,并采用XLU embeddings编码token,其中XLU embeddings采用的是预训练的MUSE跨语言编码(引文:Conneau et al., 2017, Word translation without parallel data),由于该编码没有对泰语的版本,所以只在西班牙语上进行了实验
- Cross-lingual with encoder embeddings: 将英语和目标语言的训练样本混合后进行训练,并采用上述的三种encoder embeddings编码token,同时作为对照的ELMo编码也会在西班牙语上进行实验

对西班牙语而言,使用target only的训练数据,ELMo由于在庞大的单语言语料上进行预训练,取得了最好的效果;而如果看跨语言的训练表现,会发现翻译训练语料的方法在意图分类和领域分类上取得了更好的效果,但对于槽填充则没有,作者认为原因可能是在slot映射的时候引入了噪声。
总体上来看,使用跨语言的训练方法都相比target only的设定取得了更好的性能,但采用何种embedding type,单语或者双语,对模型的最终性能相对来说影响不大。
the benefit of cross-lingual training comes from sharing the biLSTM layer or the CRF layer and that embed-ding the tokens of the high-resource and the low-resource language in a similar space is not as important.
Zero-shot learning and learning curves
从上一个实验看来,单单使用全部的目标语言训练样本,无法清楚的看出跨语言的编码是否有帮助。因此作者做了第二个实验,也就是使用更少的数据量的学习。
首先是zero-shot的实验结果,即:不使用任何目标语言训练样本,单单采用英语的训练数据,其实验结果如下图:
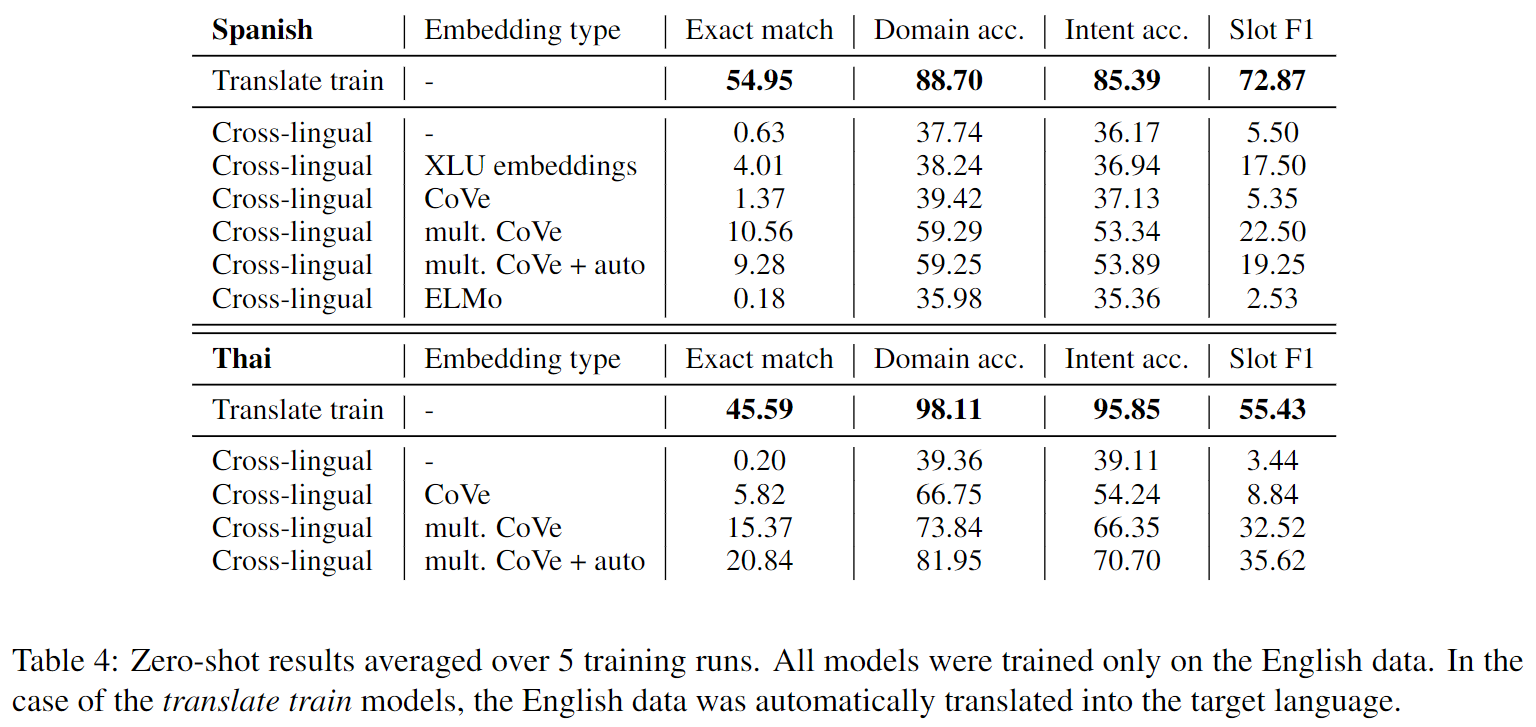
可以看到预训练的两种跨语言CoVe编码是超过单语言的CoVe编码的,证明了跨语言的编码相比单语言编码还是有所帮助的,同时可以在西班牙语的实验结果上看到这两种跨语言的CoVe编码,在zero-shot的情况下比XLU embeddings的效果更好。另外,意料之中,机器翻译(Translate train)的方法在zero-shot时取得了最好的效果。
Conclusion
本文主要解决的是SLU(Spoken Language Understanding)的跨语言迁移,即针对于同一领域从高资源语言SLU迁移到低资源语言SLU,构建了一个英语、西班牙语、泰语的平行语料。实验证明多语言联合训练能够持续地提升模型表现,但是单语或多语预训练embedding影响不大。